출처:
https://herbwood.tistory.com/10
Faster R-CNN 논문(Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks) 리뷰
이번 포스팅에서는 Faster R-CNN 논문(Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks)을 읽고 정리해봤습니다. 기존 Fast R-CNN 모델은 여전히 Selective search 알고리즘을 통해 region proposals
herbwood.tistory.com
R-CNN의 단점
1) 2000개의 RoI 각각을 CNN 통과 (시간이 오래걸림)
2) 강제 warping (성능 손실 가능성)
3) CNN, SVM classifier, bbox regression 따로 학습
4) end-to-end 불가능
Fast R-CNN의 개선점
1) 2000개의 RoI 각각을 CNN 통과 (시간이 오래걸림)
> 이미지 전체를 한 번만 CNN 통과
> Region Proposal&RoI Projection: 원본에서 selective search로 찾은 RoI를 CNN을 통과한 feature map에 project 시킴
2) 강제 warping (성능 손실 가능성)
> RoI pooling: 지정한 크기의 그리드로 나눈 후 max pooling하여 (강제 warping 할 필요 없이) 고정된 크기의 feature map 출력

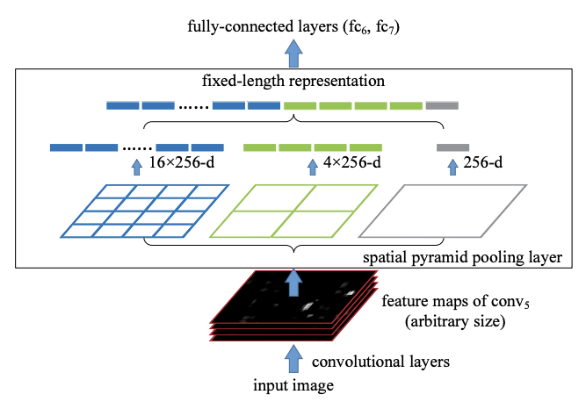
3) CNN, SVM classifier, bbox regression 따로 학습
> RoI pooling 후 fully connected layer, softmax classifier, bounding box regressor
> 따로 학습할 필요 없음
>>> 위 알고리즘 중 2번과 3번은 Faster R-CNN에서도 사용함
>>> end-to-end traing에 bottleneck 문제 아직 존재. Faster R-CNN에서 해결해보자!
Faster R-CNN

- Fast R-CNN이 end-to-end training에서 bottleneck이 있는 이유는 selective search가 CPU상에서만 돌아가는 알고리즘이고, 이로 인해 네트워크 병목현상이 일어나기 때문
- Faster R-CNN은 이를 해결하기 위해 Region Proposal Network(RPN)을 제안
RPN
- 원본 이미지에서 region proposal을 추출하는 네트워크
- summary:
> 원본 이미지를 그리드로 나눠서 각 그리드마다 9개의 anchor box를 추출함
> region proposal에 대해 class score을 매기고 bounding box coefficient를 출력
anchor box

- 세 개의 aspect ratio와 scale의 조합으로 총 9개의 anchor box 존재
- 다양한 크기로 다양한 크기의 객체를 포착할 수 있음

- 원본 이미지와 CNN을 통과한 feature map의 sub-sampling ratio에 따라서 grid를 나눔
- anchor box는 원본 이미지의 각 grid cell의 중심을 기준으로 생성
ex. 원본 이미지 600x800, sub-sampling ratio 1/16
> anchor가 생성되는 수 = 600/16 x 800/16 = 1900
> anchor box의 수 = 1900 x 9 = 17100
Steps
1. 원본 이미지를 pretrained VGG 모델에 입력하여 feature map 추출
ex. 원본 이미지 800x800, sub-sampling ratio 1/100 -> 8x8x512 feature map
2. 1에서 얻은 feature map에 대해 3x3 conv 연산 적용 (feature map 크기 유지를 위해 padding 추가)
ex. 8x8x512 feature map - 3x3 conv -> 8x8x512 feature map
3. class score를 매기기 위해 feature map에 대해 1x1 conv 연산 적용.
이 때 channel 수가 2x9(물체가 있는지 없는지 x anchor box 개수)이 되도록 함.
각 grid cell에 anchor box 9개
ex. 8x8x512 feature map - 1x1 conv -> 8x8x2x9 feature map = class scores
4. bounding box regressor를 얻기 위해 feature map에 1x1 conv 연산 적용.
channel수가 4x9(bounding box regressor x anchor box 개수)가 되도록 함.
ex. 8x8x512 feature map - 1x1 conv -> 8x8x4x9 feature map = bounding box regressors
Results

left) anchor box 종류에 따라 객체 포함 여부를 나타냄
right) anchor box 종류에 따라 bounding box regressor를 나타냄
전체적인 Faster R-CNN training 과정
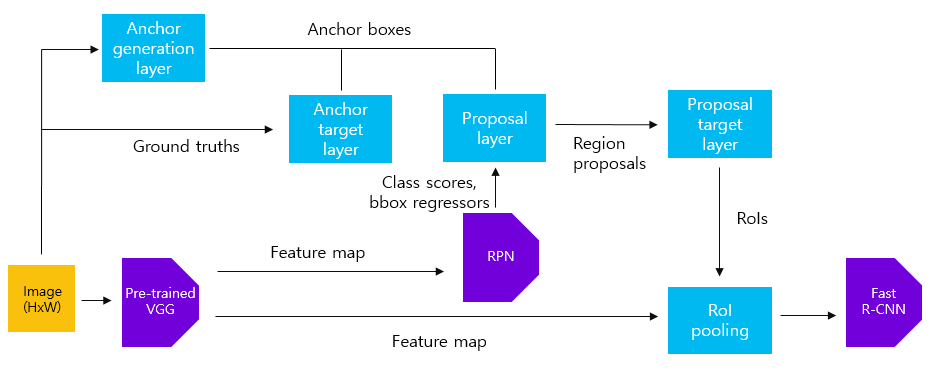
1. Feature extraction by pretrained VGG16
- input: 800x800x3 img, sub-sampling ratio 1/16
- output: 50x50x512 feature map
2. generate anchors by anchor generation layer
원본 이미지에 대해 anchor box를 생성하는 과정.
원본 이미지에 sub-sampling ratio를 곱한만큼의 grid cell이 생성되고, grid cell마다 9개의 anchor box가 생성됨
- input: 800x800x3 img, sub-sampling ratio 1/16
- output: 50x50x9 = 22500 anchor boxes
3. class scores and bounding box regressor by RPN
- input: 50x50x512 feature map
- output: class scores(50x50x2x9 feature map), bounding box regressors(50x50x4x9 feature map)
4. region proposal by proposal layer
RPN에서 반환한 class scores와 bounding box regressors를 사용해 region proposal을 추출.
Non-Maximum Suppression으로 부적절한 box를 제거, class score 상위 N개의 anchor box 추출.
Regression coefficients를 통해 anchor box들의 위치를 fine-tuning함.
- input: 50x50x9 = 22500 anchor boxes,
class scores(50x50x2x9 feature map), bounding box regressors(50x50x4x9 feature map)
- output: top-N ranked region proposals
5. Select anchors for training RPN by anchor target layer
anchor target layer의 목표는 RPN이 학습하는데 사용할 수 있는 anchor를 선택하는 것.
2에서 생성한 anchor box들 중 원본 이미지의 경계를 벗어나지 않는 anchor box 선택.
positive sample = 객체가 존재하는 foreground / negative sample = 객체가 없는 background
ground truth box와 가장 큰 IoU 값을 가지는 경우 OR ground truth box와의 IoU 값이 0.7 이상인 경우 positive,
0.3 이하인 경우에는 negative, 나머지의 경우는 무시함. (=positive/negative data sampling)
- input: anchor boxes, ground truth boxes
- output: positive/negative samples with target regression coefficients
6. Select anchors for training fast R-CNN by proposal target layer
proposal target layer의 목표는 proposal layer에서 나온 region proposal 중 fast R-CNN 모델을 학습시키기 위한 sample을 선택하는 것.
선택된 region proposal은 1에서 출력한 feature map에 RoI pooling을 수행.
region proposal과 ground truth box와의 IoU가 0.5 이상이면 positive, 0.1~0.5인 경우 negative.
- input: top-N ranked region proposals, ground truth boxes
- output: positive/negative samples with target regression coefficients
7. max pooling by RoI pooling
1에서 추출한 feature map과 6에서 얻은 sample로 RoI pooling 수행.
고정된 크기의 feature map이 나옴.
- input: 50x50x512 feature map
positive/negative samples with target regression coefficients
- output: 7x7x512 feature map
8. train fast R-CNN by multi-task loss
입력받은 feature map을 fc layer에 입력하여 4096 크기의 feature vector 추출.
feature vector를 classifier & bounding box regressor에 입력하여 k+1, (k+1)x4 크기의 feature vector 출력 (k = class 수)
출력된 결과와 multi task loss를 통해 fast R-CNN 모델을 학습.
- input: 7x7x512 feature map
- output: loss (RPN loss + RoI loss)

Inference 과정

inference 단계에서는 anchor/proposal target layer는 사용되지 않음.
둘은 네트워크를 학습시키기 위한 데이터셋을 구성하는데 사용되기 때문.
Proposal layer에서 추출한 region proposal로 detection 수행, NMS를 통해 최적의 bounding box만을 결과로 출력.
'Object detection' 카테고리의 다른 글
| Ensemble strategies (0) | 2022.11.27 |
|---|---|
| Shell script command - sed (0) | 2022.11.26 |
| Github branch & sh 파일 & argparse 만들기 (0) | 2022.11.21 |
| FPN (0) | 2022.11.17 |
| Pre-course research (0) | 2022.11.11 |

